
深度学习基础
概念关系
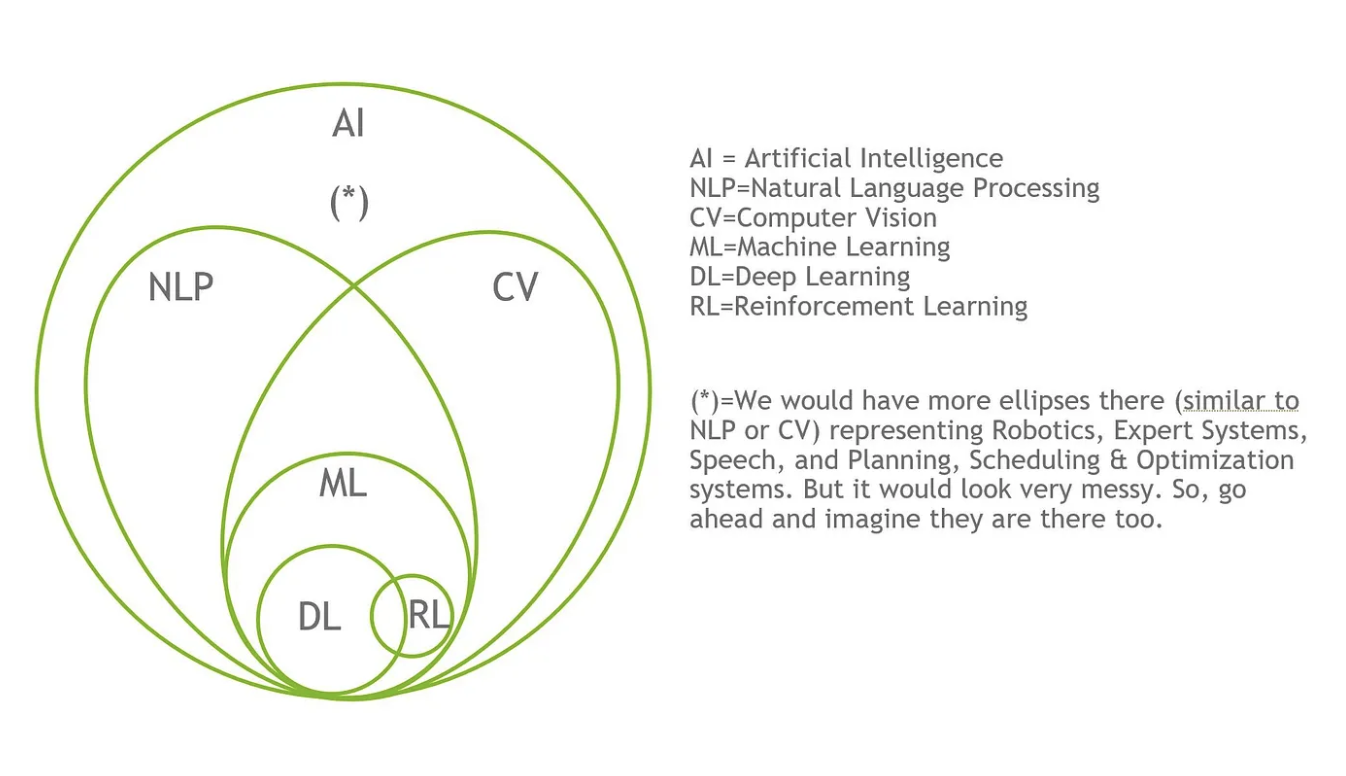
人工智能、机器学习、深度学习
深度学习只是人工智能领域的一个子集。
AI > ML > DL CV NLP
AI:人工智能,包括机器学习、深度学习、强化学习、统计学习、计算机视觉、自然语言处理、语音识别、语音合成、无人驾驶等。
ML:机器学习,是指让计算机学习,从数据中提取知识,并应用到新的任务中,以达到预测、分类、聚类、回归等目的。
DL:深度学习,是指让计算机学习深层次的特征,并用这些特征来解决复杂的任务。
CV:计算机视觉,是指让计算机理解和处理图像、视频、声音等信息,从而实现智能视觉、智能分析、智能识别等功能。
NLP:自然语言处理,是指让计算机理解和处理人类语言,包括文本、音频、视频等,从而实现智能语言、智能问答、智能聊天等功能。
CV、NLP 属于人工智能的交叉领域。
传统机器学习和深度学习区别
传统机器学习:输入 特征提取器 学习器 输出
深度学习: 输入 简易特征提取器 额外的特征提取层 学习器(多层神经网络) 输出
传统机器学习:
- 基于规则:基于规则的机器学习算法,如决策树、随机森林、支持向量机等,通过定义一系列的规则来对输入数据进行分类或预测。
- 基于统计:基于统计的机器学习算法,如线性回归、逻辑回归、朴素贝叶斯等,通过对输入数据进行统计分析,对数据进行建模,并根据模型对未知数据进行预测。
深度学习: - 基于神经网络:深度学习算法,如卷积神经网络、循环神经网络、递归神经网络等,通过构建多层神经网络来对输入数据进行分类或预测。
- 基于深度学习:深度学习算法,如深度置信网络、深度学习框架TensorFlow、PyTorch等,通过对输入数据进行深层次的特征学习,并用这些特征来解决复杂的任务。
传统机器学习和深度学习的区别:
- 算法:传统机器学习算法以规则和统计为基础,深度学习算法以神经网络为基础。
- 训练:传统机器学习算法需要大量的训练数据,深度学习算法不需要大量的训练数据,只需要对输入数据进行少量的训练。
- 预测:传统机器学习算法可以对未知数据进行预测,深度学习算法可以对未知数据进行分类或预测。
- 复杂度:传统机器学习算法的复杂度往往依赖于规则和统计的复杂度,深度学习算法的复杂度则依赖于神经网络的复杂度。
为什么深度学习可以用来做图像识别
深度学习的核心思想是通过学习数据的复杂结构,从而对输入数据进行抽象和特征化,从而实现对未知数据进行预测或分类。
图像识别的任务就是识别图像中的物体,传统机器学习算法往往需要大量的训练数据才能实现较好的效果,而深度学习算法不需要大量的训练数据,只需要对输入数据进行少量的训练,就可以实现较好的效果。
深度学习算法可以从图像的全局、局部、边缘等不同层次进行抽象,从而提取图像的特征,并用这些特征来进行分类或预测。
正常很多情况下会碰到图片的背景比较复杂,这时候很多传统算法就很容易失效,为了去除噪声,提升图片质量可能需要做大量的工作还不一定成功,而且数据标注难度极大。深度学习,不需要关系噪声,直接把样本丢进去学,最后网络取得的效果大多会比较好,并且具有一定的抗噪能力。
深度学习
深度学习步骤
y = kx + b,k 和 b 是模型参数,需要通过训练找到最优参数。
无论是深度学习,还是传统机器学习,都可以分为以下步骤:
- 准备数据集(DataSet)
- 模型(Model)
- 训练(Training
- 推理(Inference)
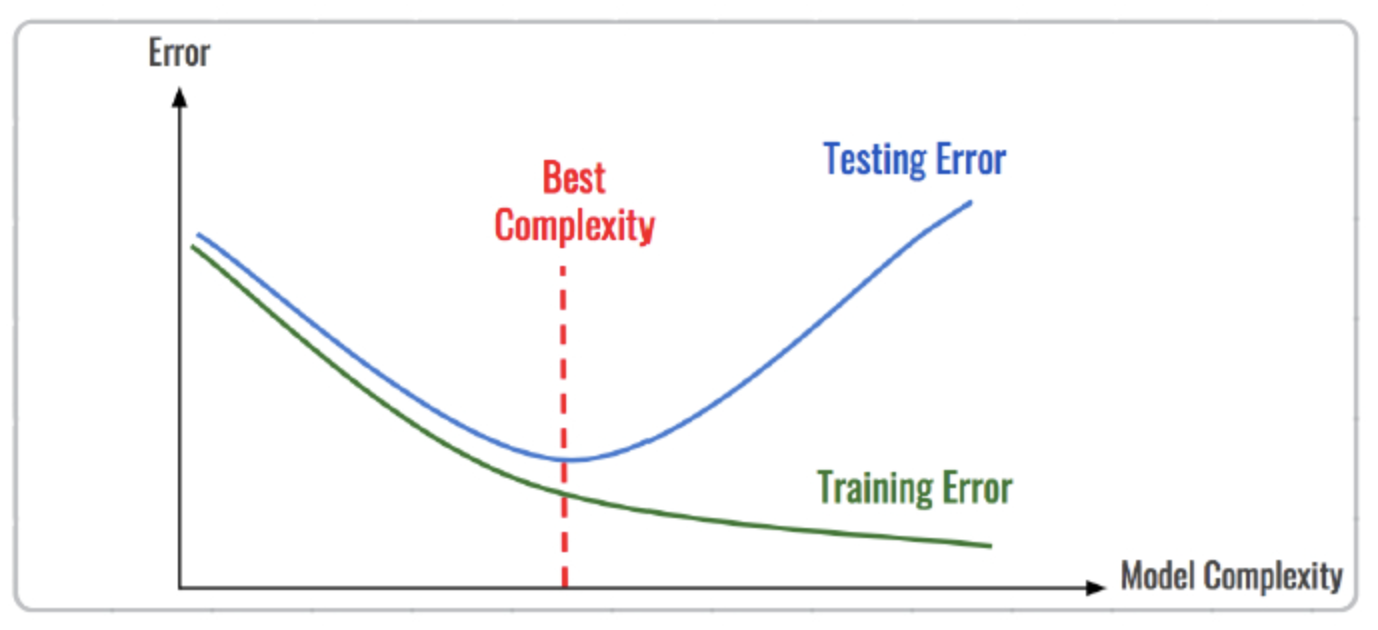
过拟合与泛化
训练和推理过程中可能会遇到一个致命问题:过拟合与泛化。
- 过拟合:模型在训练过程中,会学习到训练数据中的噪声,导致模型在测试数据上表现不佳。
- 泛化:模型在训练过程中,会学习到训练数据中的规律,导致模型在新数据上表现不佳。
解决过拟合的方法:
- 早停法(Early Stopping):在训练过程中,每过一段时间,评估模型在验证集上的性能,如果验证集上的性能没有提升,则停止训练。
- 正则化(Regularization):通过限制模型的复杂度,来减少过拟合。
- 数据增强(Data Augmentation):通过对训练数据进行变换,来增加训练数据量,从而减少过拟合。
解决泛化的方法:
- 交叉验证(Cross Validation):将数据集分为训练集、验证集、测试集,分别训练模型,并在测试集上评估模型的性能。
- 集成学习(Ensemble Learning):通过多个模型的集成,来提升模型的泛化能力。
从线性模型认识损失(loss)
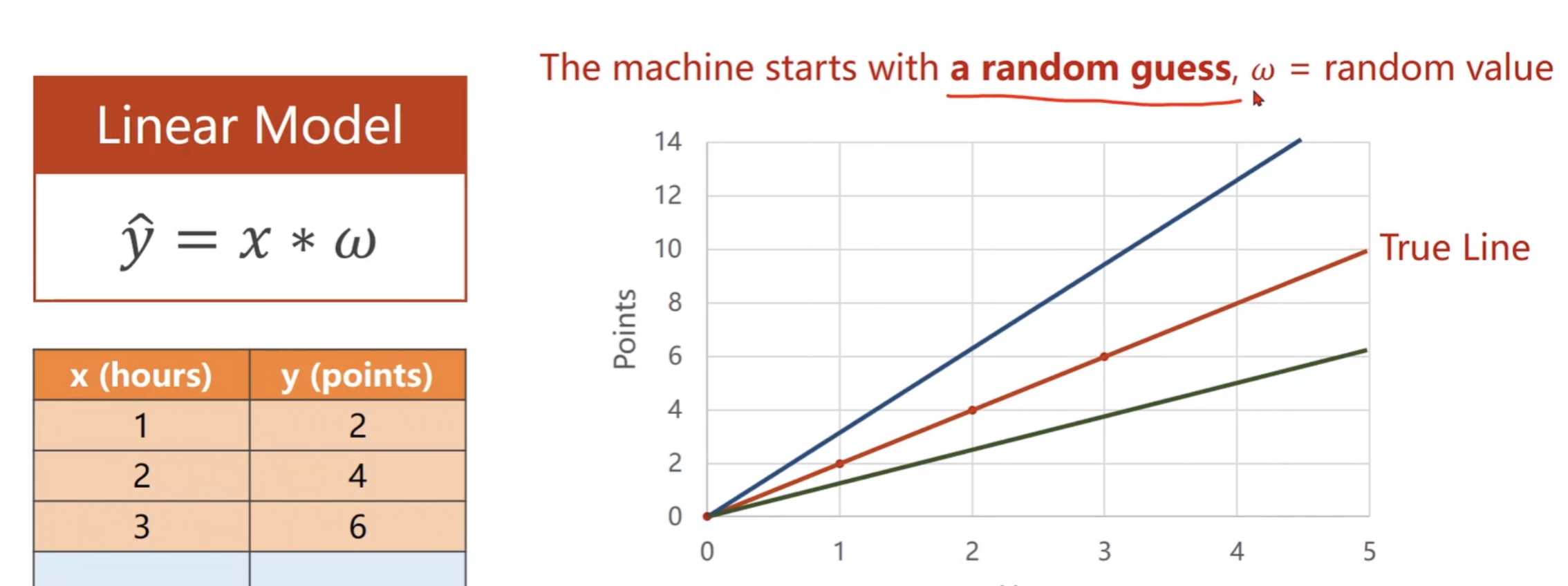
训练中目的就是将损失最小化,损失函数衡量模型预测值与真实值之间的差距。
损失函数的选择:
- 回归问题:均方误差(MSE)、绝对值误差(MAE)
- 分类问题:交叉熵(Cross Entropy)、F1-score
训练与测试准确度大致分步
深度学习到底是在干什么
一言以蔽之,即计算权重。深度学习的核心是计算权重,即通过学习数据中的复杂结构,来计算出模型的权重,从而实现对未知数据进行预测或分类。